本篇會講一些Google提供的機器學習之環境到底是怎樣,如何協助我們。
文章:Production ML Systems
這是課程中描繪的圖片: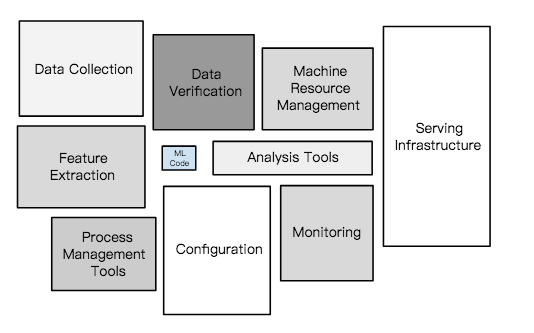
明顯的看得出來,中間的「ML code」其實對於整個機器學習的系統是十分渺小,他們提到甚至不到5%。
經過了十幾天,其實有發現一件事情,就是在討論機器學習的公式非常的少,大部分都是在說如何製作,如何計算,如何整理資料,如何分類資料等等作業。
光是收集,還有整理資料就要花費一堆功夫,十分令人頭大(可以參考:【Day12】2rd:泛化(Generalization)
、【Day15】2rd:表現(Representation)
、【Day16】2rd:特徵十字(Feature Crosses)
、【Day17】2rd:特徵十字(Feature Crosses)# 2 -One-Hot Vectors
等系列文章)。雖然步驟多,且花費一堆時間,但幸運的是可以有很多工具使用,所以就讓我們真正需要動腦的部份,就是在核心:訓練模型、資料整理與解析等等較為精細的作業。
所以圖中的東西多,但是不一定我們都要做,可以說幾乎所以步驟都有工具可以協助,除了 TensorFlow 提供許多組件外,但是其他的像是Spark或Hadoop也是現在很流行使用的。
可以參考上一篇文章(【Day18】2rd:Feature Crosses #3-遊戲時間
),我們使用了他們整理好的數據模組,還有Google準備好的超參數欄位,而我們只要在這些欄位中換數值即可,並且可以根據不同的數據內容進行訓練。雖然只是初期學習,但是可以看得出來,我們並沒有深入去實作每一個動作,這些都是有套件或是模組幫我們實現。不只是學習,在跨入真實世界中的機器學習相信也是不會如想像那麼難。因此第二個部分現在這邊停止,理論的東西等之後有時間再討論,現在來試看看Google的機器學習工程(Machine Enigneering)吧
睫毛之聲:
(剛好身邊有Spark大師在,不懂就可以請教他!)
現在開始短短的新的一章,不然再下去理論的話,可能完賽都還在算數學

